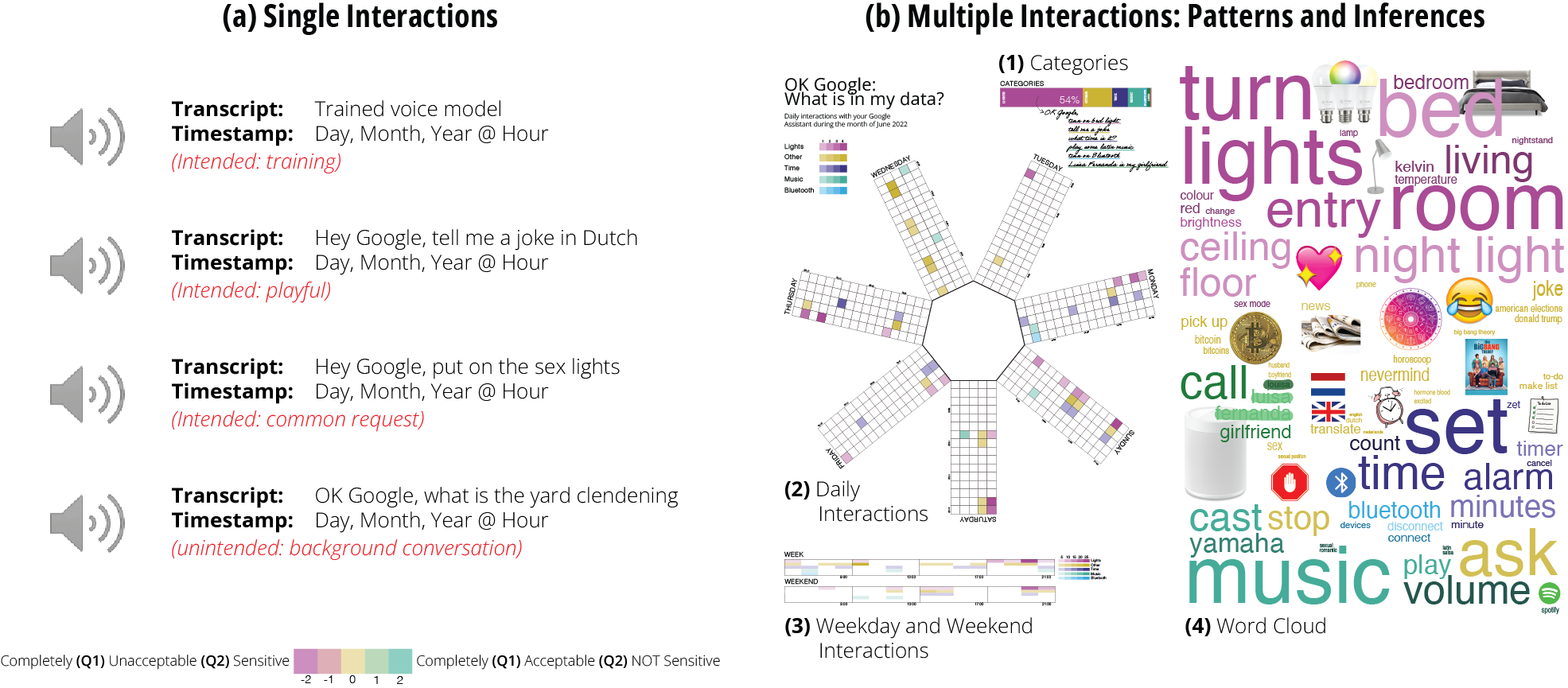
Digital technologies have increasingly integrated into people’s lives, continuously capturing their behavior through potentially sensitive data. In the context of voice assistants, there is a misalignment between experts, regulators, and users on whether and what data is `sensitive’, partly due to how data is presented to users; as single interactions. We investigate users’ perspectives on the sensitivity and intimacy of their Google Assistant speech records, introduced comprehensively as single interactions, patterns, and inferences. We collect speech records through data donation and explore them in collaboration with 17 users during interviews based on predefined data-sharing scenarios. Our results indicate a tipping point in perceived sensitivity and intimacy as participants delve deeper into their data and the information derived from it. We propose a conceptualization of sensitivity and intimacy that accounts for the fuzzy nature of data and must disentangle from it. We discuss the implications of our findings and provide recommendations.
Link to the CHI ‘23 conference website
Cite Bibtex
@inproceedings{10.1145/3544548.3581164,
author = {G\'{o}mez Ortega, Alejandra and Bourgeois, Jacky and Kortuem, Gerd},
title = {What is Sensitive About (Sensitive) Data? Characterizing Sensitivity and Intimacy with Google Assistant Users},
year = {2023},
isbn = {9781450394215},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3544548.3581164},
doi = {10.1145/3544548.3581164},
abstract = {Digital technologies have increasingly integrated into people’s lives, continuously capturing their behavior through potentially sensitive data. In the context of voice assistants, there is a misalignment between experts, regulators, and users on whether and what data is ‘sensitive’, partly due to how data is presented to users; as single interactions. We investigate users’ perspectives on the sensitivity and intimacy of their Google Assistant speech records, introduced comprehensively as single interactions, patterns, and inferences. We collect speech records through data donation and explore them in collaboration with 17 users during interviews based on predefined data-sharing scenarios. Our results indicate a tipping point in perceived sensitivity and intimacy as participants delve deeper into their data and the information derived from it. We propose a conceptualization of sensitivity and intimacy that accounts for the fuzzy nature of data and must disentangle from it. We discuss the implications of our findings and provide recommendations.},
booktitle = {Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems},
articleno = {586},
numpages = {16},
keywords = {Personal Data, Sensitive Data, Intimate Data;, Voice Assistants},
location = {Hamburg, Germany},
series = {CHI '23}
}